Hackathon notes
Why choosing Langchain JS Over Teams AI library for LLM Orchestration?
We found Langchain to be more user-friendly and closely aligned with core LLM concepts compared to the Teams AI library, particularly in terms of tools management. Additionally, Langchain's documentation is superior, offering clear usage examples. The only drawback is that integrating Langchain with Bot Framework features to build an end-to-end chat solution requires more effort.
Why choosing 'botbuilder' (Bot Framework V4) over the new '@microsoft/agents-hosting' SDK (Microsoft 365 Agents SDK)?
We initially started building our solution using the new Microsoft 365 Agents JavaScript SDK. However, we quickly realized it wasn't the best option for us due to several limitations:
- Lack of parity with the traditional Bot Framework: The SDK didn't allow us to easily achieve our goals, such as proactive notifications and conversation flows. We spent too much time figuring out how to accomplish tasks that were straightforward with the Bot Framework. Unfortunately, there is no migration guide available yet to assist with the transition. Given these challenges, we decided to stick with the familiar territory for time reasons.
- No tooling: The Microsoft Agents 365 SDK is not integrated with the Teams Toolkit, making it harder to develop solutions quickly.
- Too much confusion between Teams AI library/Microsoft 365 Agents SDK/Bot Framework: Online, you'll find numerous "agents" samples using various technology stacks (e.g., M365 Agents SDK samples, Teams AI library samples, Bot Framework samples). This can be very misleading for developers, as it creates confusion about which technology to use. In reality, developers often end up mixing concepts from all these samples.
Ultimately, we concluded that the Microsoft 365 Agents SDK was not ready yet for the purpose of this hackathon.
What challenges did we face?
During the development, we actually faced many challenges!
Handling different JSON tool outputs with LLM and adaptive cards
In the solution, actions requested by the user generate different UI outputs from the agent (sometimes just text, sometimes adaptive cards with heteregonous JSON formats). The challenge was to adapt these different outputs returned by LLM/tools to the correct UI in Teams:
Adaptive cards for list of assigned tasks
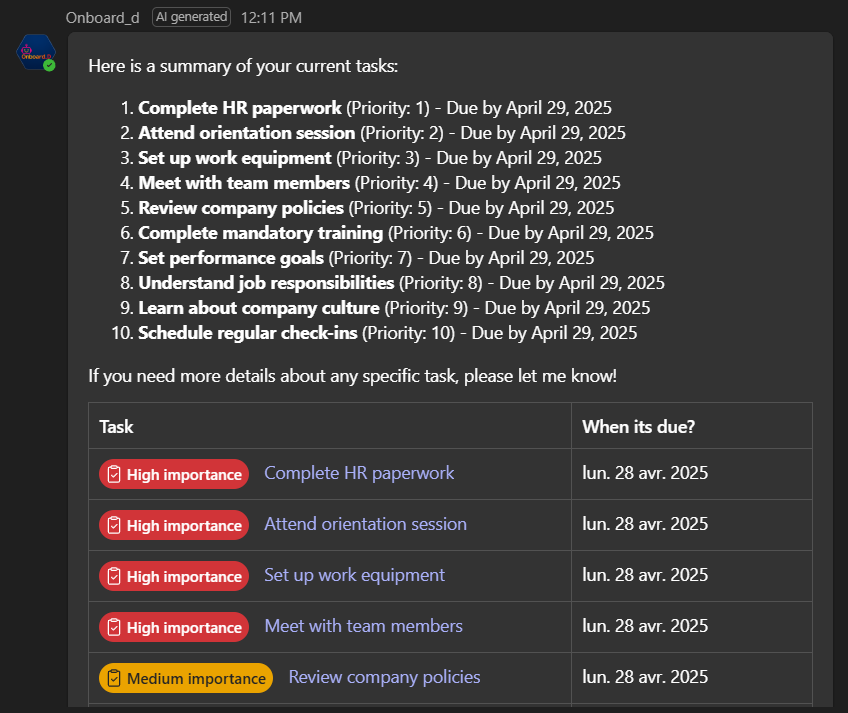
Adaptive cards for task details
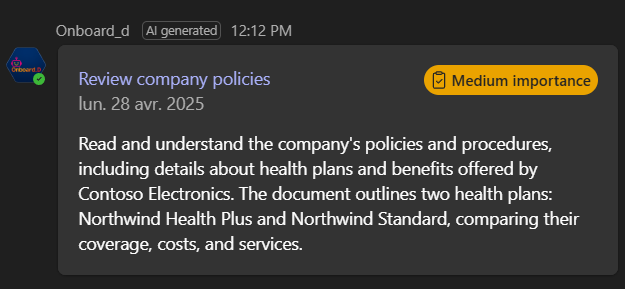
Because the data format was dynamic, we couldn't use a structured output for all the LLM answers (using either Langchain structured outputs or OpenAI json_schema). For direct 1:1 mapping (tool output->adaptive card), we used the 'artifact' feature of Langchain to map the data returned by tools directly to adaptive cards. Letting the LLM figure out the JSON format to pass to the card was not efficient and not reliable. Here is an example how we manage tools JSON outputs:
// Tool output
export const getUserTasks = tool(
async (args: any, config: RunnableConfig) => {
tasks = await plannerService.getPlanTasks(planId);
...
return [
`Successfully retrieved array of ${tasks.length} tasks ${JSON.stringify(tasks.map(t => { return { id: t.id, title: t.title, references: t.references, dueDateTime: t.dueDateTime }}))} assigned to the user.`, // Returned to the LLM
tasks // Artifact
];
},
...
// Usage in adaptive card
case AgentTools.GetTasksForUsers:
card = AdaptiveCards.declare<any>(NotificationMessageAdaptiveCard).render({ answer: llmResponseContent, data: llmResponse.messages[lastIndex].artifact});
...
For responses requiring multiple tools to be invoked sequentially (e.g., retrieving task details involves using two tools: GetTaskDetails to obtain task attributes like title, due date, etc., and SearchReferenceContent to locate content from referenced documents in the search index, culminating in a comprehensive summary that incorporates all the gathered information), rather than directing the model to generate a JSON output, we introduced an additional tool, GetTaskStructuredOutput, to format the data from the previously invoked tools into a structured output.
export const getTaskStructuredOutput = tool(
async (args: { task: any}) => {
return [
"Task formatted successufly",
args.task
]
},
{
name: AgentTools.GetTaskStructuredOutput,
description: 'Format a task as structured output',
responseFormat: "content_and_artifact",
schema: z.object({
task: z.object({
title: z.string().describe(`title extract from the task`).nullable(),
summary: z.string().describe(`generated summary of what user needs to do according to task description extract and retieved content from references if available. Text only, no markdown`).nullable(),
priority: z.number().describe(`priority extract from the task data`).nullable(),
startDateTime: z.string().describe(`start date extract from the task data`).nullable(),
dueDateTime: z.string().describe(`due date extract from the task data`).nullable(),
deepLink: z.string().describe(`link extract from the task data`).nullable()
}).nullable()
}).describe("the task details")
}
)
This tool establishes a clear schema outlining the expected data and returns it in its original form, ensuring it can be safely used as an artifact. We discovered that this method was significantly more efficient than having the LLM generate a JSON output. The truly challenging aspect, which required multiple attempts, was getting the LLM to utilize the final tool to format the output correctly. Here is the prompt we use to ensure the desired tool is employed:
...
## CAPABILITY: Get details about a specific task ##
- Examples:
- Give me more information about the "..." task.
- What is the task ..
- Waht should i do for task #5
- If not provided, you **must** ask for task ID. Otherwise, lookup the task id in your chat history or use the one provided by user before using tool.
- If a task has references, retrieve associated content passing all URLs at once and summarize the content to clearly explain what about the task is.
- Finally format the task as structured output using <GetTaskStructuredOutput> before answering.
..
Supporting both application/delegated permissions on LLM tools seamlessly
Because of the nature of the solution having both proactive notifications and direct interactions with the agent, we needed to support both delegated and application access. Even if we could have use application permissions everywhere for convenient reasons, we wanted to create a secure solution handling bot type of permissions keeping it transparent for tools:
- Delegated permissions: actions are performed on-behalf of the user when he interacts directly with the agent.
- Application permissions: actions are performed by the agent itself without any user interactions for proactive notifications.
For this, we used the RunnableConfig feature of Langchain pass parameters to tools using the following code:
- Instanciate a Microsoft Graph client like this:
// Delegated permissions
const oboCredential = new OnBehalfOfUserCredential(tokenResponse.ssoToken, oboAuthConfig);
const authProvider = new TokenCredentialAuthenticationProvider(
oboCredential,
{
scopes: [MicrosoftGraphScopes.TasksReadWrite, MicrosoftGraphScopes.SiteReadAll],
}
);
...
// Application permissions
const appCredential = new AppCredential(appAuthConfig);
const authProvider = new TokenCredentialAuthenticationProvider(appCredential, {
scopes: [MicrosoftGraphScopes.Default],
});
...
- Pass the provider to the tools when invoking the LLM:
// Pass the provider to tools
const runnableConfig = {
...
authProvider: authProvider,
};
const llmResponse = await this.agent.invoke(
{ messages: messages },
{ configurable: runnableConfig}
);
...
- Finally use it in tools:
export const getUserTasks = tool(
async (args: any, config: RunnableConfig) => {
let tasks: IPlannerTask[] = [];
// Initialize Graph client instance with authProvider (can be app or delegated permissions her depending on the caller)
const graphClient = Client.initWithMiddleware({ authProvider: config.configurable.authProvider });
const plannerService = new PlannerService(graphClient);
...
tasks = await plannerService.getPlanTasks(planId);
...
Handling 'Human-in-the-loop' pattern with regular bot dialogs
As previously mentioned, Langchain is completely agnostic to "chat implementation technology," allowing you to develop your own user interface on top of it. In our case, we utilize the Bot Framework for that aspect, incorporating bot dialogs to manage this scenario through dialog branches. If tools are chosen by the LLM, prior to execution, we ensure any tools requiring human confirmation are identified and addressed. This process is carried out as follows:
// Create a Langchain agent with prebuilt StateGraph
const aiAgent = createReactAgent({
llm: agentModel,
tools: agentTools,
checkpointSaver: agentCheckpointer,
interruptBefore: ["tools"] // Human-in-the-loop: will stop the LLM after tools selection, letting you decide what to do
});
...
Tool validation in the main agent dialog:
// Agent dialog
const llmResponse = await this.agent.invoke(
{ messages: messages },
{ configurable: runnableConfig}
);
// Check invoked tools
const toolCalls = llmResponse.messages[llmResponse.messages.length-1].tool_calls
// Data to be passed across dialogs
const modelData = {
...
toolCalls: toolCalls
} as IAgentStepData;
for (const selectedTool of toolCalls) {
// Determine which tool needs a human in the loop and an explicit confirmation to be executed
switch (selectedTool?.name) {
case 'UpdateTaskCompletion':
return await stepContext.beginDialog(HUMAN_IN_THE_LOOP_DIALOG, modelData);
default:
break;
}
}
What is left?
Our primary goal was to create a solution that is straightforward to deploy and test across any Microsoft tenant. Consequently, we couldn't incorporate all the features and improvements we had originally planned for this agent. Among among:
- Employee plan setup improvements: Improve plan setup with dynamic start dates for tasks from the template + tasks query filtering in the agent (i.e only active tasks between specific dates)
- Token Management System: A mechanism to monitor token usage and optimize costs associated with AI service consumption.
- Debugging Agent Outputs: A user-specific debug mode integrated into adaptive card responses, enabling the debugging of LLM reasoning and reviewing decisions made by the agent directly from its answers.
- Responsible AI Practices: Enhancements to refine prompts and establish safeguards to ensure the agent operates effectively within the scope of its intended objectives.
That will be for the next time!